天池大赛(I):MapReduce处理数据
2016-06-16
写在前面:本文的数据和场景来自天池-阿里音乐流行趋势预测大赛。
0. 环境说明
- CentOS 7.0 - 阿里云主机
- CentOS 6.5 - 腾讯云主机
- Hadoop 2.7.2
- JRE 1.7.0_75
其中,阿里云主机是Master节点,既作为名称节点,又作为数据节点。腾讯云主机是Slaver节点,作为数据节点。
1. 概述
赛题近似一个多维时间序列预测,现有的时间序列预测方法大多倾向于使用过去的真实值平移或者其他处理得到预测值。如果是多变量,还可能根据时间序列之间的相关性进行预测。
1.1 模型假设
对这个问题做如下假设:
用户的行为存在频繁模式,且视为布尔型关联规则。存在这样的情况,用户当日播放了歌手A和歌手B的歌曲后,更倾向于播放歌手C的歌曲。(A, B)=>C是一种关联规则。(A, B, C)就是一种频繁模式。
事务以天用户为单位,即某一用户当日播放歌曲所属的歌手的集合。
同一频繁模式下的两个歌手的日播放量会相互影响。
(我们还应当统计每一个歌手对用户的吸引度,以用户连续播放该歌手的音乐的持续天数的概率分布来表示。比如我们统计出100次不间断播放行为中,有10次连续播放了5天,20次连续播放了4天,20次连续播放3天,20次连续播放2天,30次连续播放1天。假如我们要用前5天的数据预测,就是0.1A1+0.2A2+0.2A3+0.2A4+0.3*A5。)
2. 预处理
2.1 从CSV到Hadoop
2.1.1 数据格式
CSV文件中的一行是这样的:
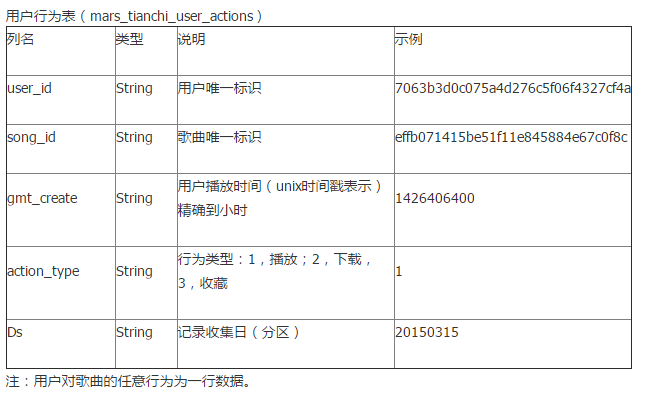
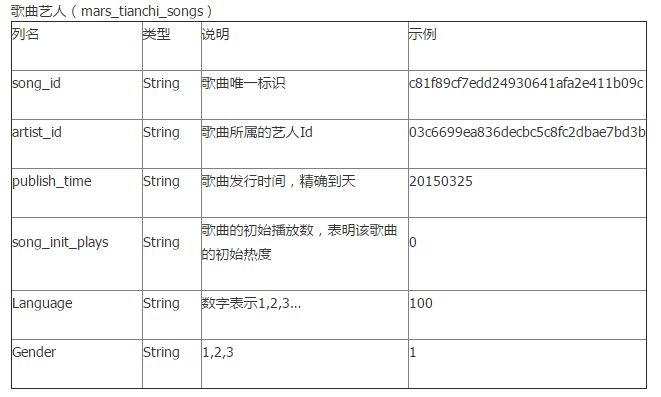
(需要确认Ds和gmt_create是不是同一天)
我们希望的数据结构形式是这样的:
|user_id |Ds | set_(artist_id:play_count)| |:--------|--------|---------|
以及垂直数据格式:
|artist_id |Ds | set_(user_id:play_count)|play_sum| |:--------|--------|---------|---------|
2.1.2 csv导入MySQL数据库
为了方便查询,我们还是需要把csv导入数据库。(主要是我们处理的数据量很少,实际上用不到Hadoop的,但是天池线上赛会用到ODPS,所以这里需要熟悉MapReduce结构)
create database `tianchi`;
use tianchi;
CREATE TABLE `tianchi`.`mars_tianchi_songs` (
`song_id` VARCHAR(64) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL ,
`artist_id` VARCHAR(64) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL ,
`publish_time` VARCHAR(64) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL ,
`song_init_plays` VARCHAR(64) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL ,
`Language` VARCHAR(64) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL ,
`Gender` VARCHAR(64) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL ,
PRIMARY KEY (`song_id`)
) ENGINE = InnoDB;
delete from mars_tianchi_songs;
load data infile '/storage/tianchi/data/mars_tianchi_songs.csv' into table mars_tianchi_songs fields terminated by ',' optionally enclosed by '"' escaped by '"' lines terminated by '\n';
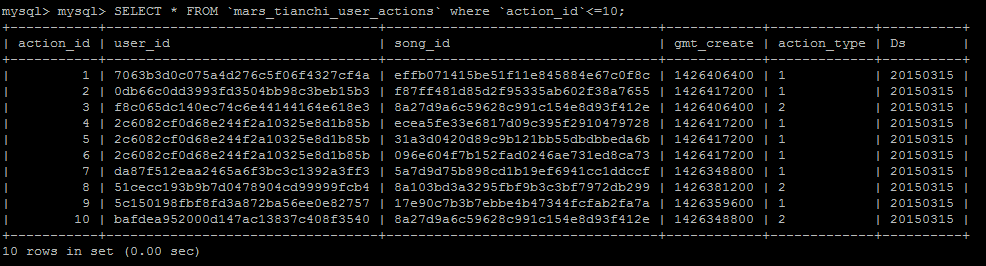
CREATE TABLE `tianchi`.`mars_tianchi_user_actions` ( `action_id` INT NOT NULL AUTO_INCREMENT , `user_id` VARCHAR(64) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL , `song_id` VARCHAR(64) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL , `gmt_create` VARCHAR(64) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL , `action_type` VARCHAR(64) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL , `Ds` VARCHAR(64) CHARACTER SET utf32 COLLATE utf32_general_ci NOT NULL , PRIMARY KEY (`action_id`)) ENGINE = InnoDB;
load data infile '/storage/tianchi/data/mars_tianchi_user_actions.csv' into table mars_tianchi_user_actions fields terminated by ',' optionally enclosed by '"' escaped by '"' lines terminated by '\n' (user_id, song_id, gmt_create, action_type, Ds);
保存为tianchi.sql。
mysql -u root -p
> source /storage/tianchi/data/tianchi.sql
2.1.3 用Hadoop处理数据
当然我们也可以使用Hadoop处理数据,实际上小于1TB的数据完全没有必要使用Hadoop,我们的目的是构造一个可以在Hadoop上使用的FP算法,后续会在Mahout上继续研究。得到例如:
| Key | Value |
|---|---|
| affair_id | artists_set |
这样的结构。affair_id用user_id和Ds组合(其实可以Hash一下)得到。
首先我们把csv文件上传到HDFS:
hdfs dfs -mkdir /tianchi
hdfs dfs -mkdir /tianchi/mars_tianchi_songs
hdfs dfs -mkdir /tianchi/mars_tianchi_user_actions
hdfs dfs -mkdir /tianchi/mars_tianchi_affairs
hdfs dfs -put /storage/tianchi/data/mars_tianchi_songs.csv
hdfs dfs -put /storage/tianchi/data/mars_tianchi_user_actions.csv
MapReduce程序包括两个Mapper:SongsMapper和ActionsMapper,一个Reducer:AffairReducer。
其中,SongsMapper用于获取<song_id, artist_id>的键值对;ActionsMapper获取<actions_id, song_id>的键值对。然后AffairReducer连接两个Mapper的输出,得到<affair_id, artists_set>。
SongsMapper实现如下:
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reporter;
/**
* <p>Title: SongsMapper.java</p>
* <p>Description: 重写Mapper接口,实现map()方法,从mars_tianchi_songs文件得到键值对。</p>
* <p>Copyright: Copyright (c) 2007</p>
* <p>Company: Zhongwei</p>
* @author Zhongwei
* @date 2016年6月15日
* @version 1.0
*/
public class SongsMapper extends Mapper<LongWritable, Text, Text, Text> {
private String delimiter = null;
@Override
public void setup(Context context)
{
delimiter = context.getConfiguration().get("delimiter", ",");
}
/**
* @MethodName : public void map(LongWritable key, TextArrayWritable value, OutputCollector<Text, Text> output, Reporter reporter) throws IOException
* @Description : 读取mars_tianchi_songs.csv每一行各个字段数据,song_id和artist_id分别作为键值。
* @param args : LongWritable key, TextArrayWritable value, OutputCollector<Text, Text> output, Reporter reporter
*/
public void map(LongWritable key, Text value, OutputCollector<Text, Text> output, Reporter reporter)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
String[] values = value.toString().split(delimiter);
Text resultKey = new Text(values[0]);
Text resultValue = new Text(values[1]);
output.collect(resultKey,resultValue);
}
}
ActionsMapper实现如下:
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reporter;
/**
* <p>Title: ActionsMapper.java</p>
* <p>Description: 重写Mapper接口,实现map()方法,从mars_tianchi_user_actions文件得到键值对。</p>
* <p>Copyright: Copyright (c) 2007</p>
* <p>Company: Zhongwei</p>
* @author Zhongwei
* @date 2016年6月15日
* @version 1.0
*/
public class ActionsMapper extends Mapper<LongWritable, Text, Text, Text> {
private String delimiter = null;
@Override
public void setup(Context context)
{
delimiter = context.getConfiguration().get("delimiter", ",");
}
/**
* @MethodName : public void map(LongWritable key, TextArrayWritable value, OutputCollector<Text, Text> output, Reporter reporter) throws IOException
* @Description : 读取mars_tianchi_user_actions.csv每一行各个字段数据,user_id和Ds字段组合后作为新键,对应的song_id作为新值。
* @param args : LongWritable key, TextArrayWritable value, OutputCollector<Text, Text> output, Reporter reporter
*/
public void map(LongWritable key, Text value, OutputCollector<Text, Text> output, Reporter reporter)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
String[] values = value.toString().split(delimiter);
Text resultKey = new Text(values[0]+values[4]);
String songId = new String(values[1]);
Text resultValue = new Text(songId);
output.collect(resultKey,resultValue);
}
}
AffairReducer实现如下:
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapreduce.Reducer;
/**
* <p>Title: AffairReduce.java</p>
* <p>Description: </p>
* <p>Copyright: Copyright (c) 2007</p>
* <p>Company: Zhongwei</p>
* @author Zhongwei
* @date 2016年6月16日
* @version 1.0
*/
public class AffairReducer extends Reducer<Text, Text, Text, Iterable<Text>> {
public void reduce(Text key, Iterable<Text> values, OutputCollector<Text, Iterable<Text>> output, Reporter reporter)
throws IOException,InterruptedException{
output.collect(key, values);
}
}
Driver的实现:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.MultipleInputs;
/**
* <p>Title: MultipleDriver.java</p>
* <p>Description: </p>
* <p>Copyright: Copyright (c) 2007</p>
* <p>Company: Zhongwei</p>
* @author Zhongwei
* @date 2016年6月16日
* @version 1.0
*/
public class MultipleDriver extends Configured implements Tool {
private static int NUM_REDUCER = 1;
private static String MARS_TIANCHI_SONGS = "/tianchi/mars_tianchi_songs/mars_tianchi_songs.csv";
private static String MARS_TIANCHI_USER_ACTIONS = "/tianchi/mars_tianchi_user_actions/mars_tianchi_user_actions.csv";
private static String MARS_TIANCHI_AFFAIRS = "/tianchi/mars_tianchi_affairs/mars_tianchi_affairs.csv";
private static String DELIMITER = ",";
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
// conf.set("fs.defaultFS", "hdfs://node33:8020");
// conf.set("mapreduce.framework.name", "yarn");
// conf.set("yarn.resourcemanager.address", "node33:8032");
ToolRunner.run(conf, new MultipleDriver(), args);
}
/**
* @MethodName : public int run(String[] arg0) throws Exception
* @Description : 运行Job,两个Mapper:ActionsMapper和SongsMapper,一个Reducer,最终的数据格式是<affair_id, artists_set>。
* @param args : String[] arg0
*/
/* (non-Javadoc)
* @see org.apache.hadoop.util.Tool#run(java.lang.String[])
*/
@SuppressWarnings({ "rawtypes" })
public int run(String[] arg0) throws Exception {
// TODO Auto-generated method stub
Configuration conf = getConf();
conf.set("delimiter", DELIMITER);
@SuppressWarnings("deprecation")
Job job = new Job(conf);
job.setJobName("tianchi");
job.setJarByClass(MultipleDriver.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(TextArrayWritable.class);//??or Text
job.setReducerClass(AffairReducer.class);
job.setNumReduceTasks(NUM_REDUCER);
Path inputSongs = new Path(MARS_TIANCHI_SONGS);
Path inputActions = new Path(MARS_TIANCHI_USER_ACTIONS);
Path output = new Path(MARS_TIANCHI_AFFAIRS);
MultipleInputs.addInputPath(job, inputSongs, TextInputFormat.class, (Class<? extends Mapper>) SongsMapper.class);
MultipleInputs.addInputPath(job, inputActions, TextInputFormat.class, (Class<? extends Mapper>) ActionsMapper.class);
FileOutputFormat.setOutputPath(job, output);
int isCompleted = job.waitForCompletion(true) ? 0 : 1;
return isCompleted;
}
/*
private void configureArgs(String[] args) {
}
*/
}
上面的TextArrayWritable是ArrayWritable的一个子类:
import org.apache.hadoop.io.ArrayWritable;
import org.apache.hadoop.io.Text;
/**
* <p>Title: TextArrayWritable.java</p>
* <p>Description: CSV文件行中各个字段的数据。</p>
* <p>Copyright: Copyright (c) 2007</p>
* <p>Company: Zhongwei</p>
* @author Zhongwei
* @date 2016年6月15日
* @version 1.0
*/
public class TextArrayWritable extends ArrayWritable {
public TextArrayWritable() {
super(Text.class);
}
public TextArrayWritable(Text[] strings) {
super(Text.class, strings);
}
}