Hadoop笔记(一)
2016-09-22
0. 写在前面
只是为面试做准备。
我的参考书目、博客和网站:
- 粉丝日志
- zhaozheng的BLOG
- 我的博客
- Apache Hadoop 2.7.2 官方文档
- 《Hadoop技术内幕:深入解析MapReduce架构设计i与实现原理》
- 《Hadoop权威指南》
- 《Hadoop MapReduce实战手册》
- 《Mahout算法解析与案例实战》
1. 什么是Hadoop?
Hadoop属于Apache的Lucene项目,是一个开发和运行处理大规模数据的软件平台。Hadoop是用Java开发的开源软件框架,可以在廉价计算机组成的集群中对海量数据进行分布式计算,其核心设计包括HDFS和MapReduce。
2. Hadoop家族包括哪些项目?简要描述它们。
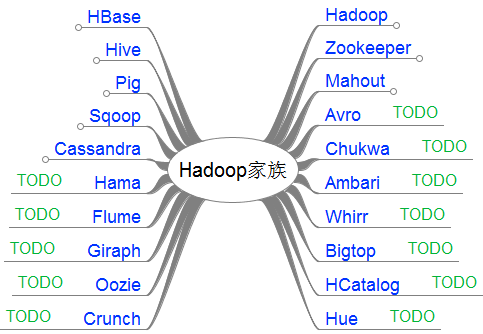
- Core:一系列分布式文件系统和通用I/O的组件和接口,包括序列化、Java RPC和持久化数据结构。
- Avro:提供高效、跨语言RPC的数据序列系统。
- MapReduce:分布式数据处理模型。
- HDFS:分布式文件系统。
- YARN:一种新的Hadoop资源管理器。总体仍然是Master/Slave结构,基本思想是将JobTracker的两个主要功能(资源管理和作业调度/监控)分离,将ResourceManager作为Master,NodeManager作为Slave,当用户提交一个应用程序时, 需要提供一个用以跟踪和管理这个程序的ApplicationMaster, 它负责向 ResourceManager 申请资源, 并要求 NodeManger 启动可以占用一定资源的任务。YARN是一个更为通用的资源管理系统。
- Pig:处理大型数据集的脚本语言。Pig Latin语言是一种表达数据流的语言,表示一系列描述数据流的操作。Pig执行环境分为两种:单个JVM本地执行或Hadoop集群分布执行。
- HBase:分布式列存储数据库。用HDFS作为底层存储,支持MapReduce的批量式计算和点查询。HBase是一个非结构化数据存储的数据库,它是一种Key/Value系统。
- Hive:数据仓库系统,提供SQL查询功能。
- ZooKeeper:分布式协同服务。可以看做服务器,可以看做库,一套API,也可以看做一个文件系统。HBase要求必须有ZooKeeper服务。
- Mahout:基于Hadoop的机器学习库。主要部分是协同过滤、推荐算法、聚类和分类。
3. 描述安装Hadoop的步骤。
安装详情见Hadoop集群部署-By zhongwei,以及Docker安装Hadoop-By zhongwei。
Master:Linux操作系统,Slave:Linux操作系统。
安装JDK和JRE,版本是1.7.0_75。
vi /etc/profile配置JAVA_HOME环境变量:
export JAVA_HOME=/usr/java/jdk1.7.0_75
保存然后sourve /etc/profile。
下载Hadoop 2.7.2,解压到
/usr/local。配置环境变量:
export HADOOP_HOME=/usr/local/hadoop-2.7.2
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
export HADOOP_LOG_DIR=/var/log/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
保存然后sourve /etc/profile。
- 建立SSH。在Master节点创建SSH密钥对,并且发送给Slave节点。
ssh keygen
ssh-copy-id localhost
ssh-copy-id slave
- 配置文件。
vi /usr/local/hadoop-2.7.2/etc/hadoop/hdfs-site.xml加入以下配置:
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///usr/hadoop/datanode</value>
</property>
</configuration>
将配置发给Slave节点:
scp usr/local/hadoop-2.7.2/etc/hadoop/hdfs-site.xml slave:usr/local/hadoop-2.7.2/etc/hadoop/
然后再在Master节点的配置中加入namenode的配置:
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///usr/hadoop/namenode</value>
</property>
</configuration>
vi /usr/local/hadoop-2.7.2/etc/hadoop/core-site.xml加入以下配置:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000/</value>
</property>
</configuration>
然后发送给Slave节点:
scp usr/local/hadoop-2.7.2/etc/hadoop/core-site.xml slaver:usr/local/hadoop-2.7.2/etc/hadoop/
mapred-site.xml文件是MapReduce后台程序设置的配置,包括jobtracker和tasktracker。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
以上配置的意思是MapReduce的执行框架设置为Hadoop YARN。最后配置yarn-site.xml文件。
修改master和slaves文件。将Master主机名或IP加入master文件,Slave加入slaves文件。
在Master节点创建存储目录:
mkdir /usr/hadoop/datanode
mkdir /usr/hadoop/namenode
ssh slaver "mkdir /usr/hadoop/datanode"
- 依次格式化名称节点,启动dfs,启动YARN,查看状态:
hdfs namenode -format
start-dfs.sh
start-yarn.sh
jps
结果显示:

4. 如何增加一个数据节点?
- 在新数据节点安装相同版本的JDK和JRE,配置环境变量。
- 下载相同版本Hadoop,用Master的配置文件覆盖。
- 配置SSH。
- 将新节点的IP加入Master节点的slaves文件。
- 从Master节点重新启动
start-dfs.sh。 - hdfs再平衡。
5. 如何安全删除一个数据节点?
利用exclude文件:
1. 在Master节点上创建一个exclude文件,并在conf/hdfs-site.xml中添加如下配置:
<property>
<name>dfs.hosts.exclude</name>
<value>[FULL_PATH_TO_THE_EXCLUDE_FILE]</value>
</property>
- 添加要删除的节点到
exclude文件。 - 运行以下命令:
hadoopdfsadmin -refreshNodes
可以更新配置不影响正常任务。
4. 如果想要恢复则从exclude文件删除节点重新执行以上命令。
6. 简要描述Hadoop源代码组织结构。
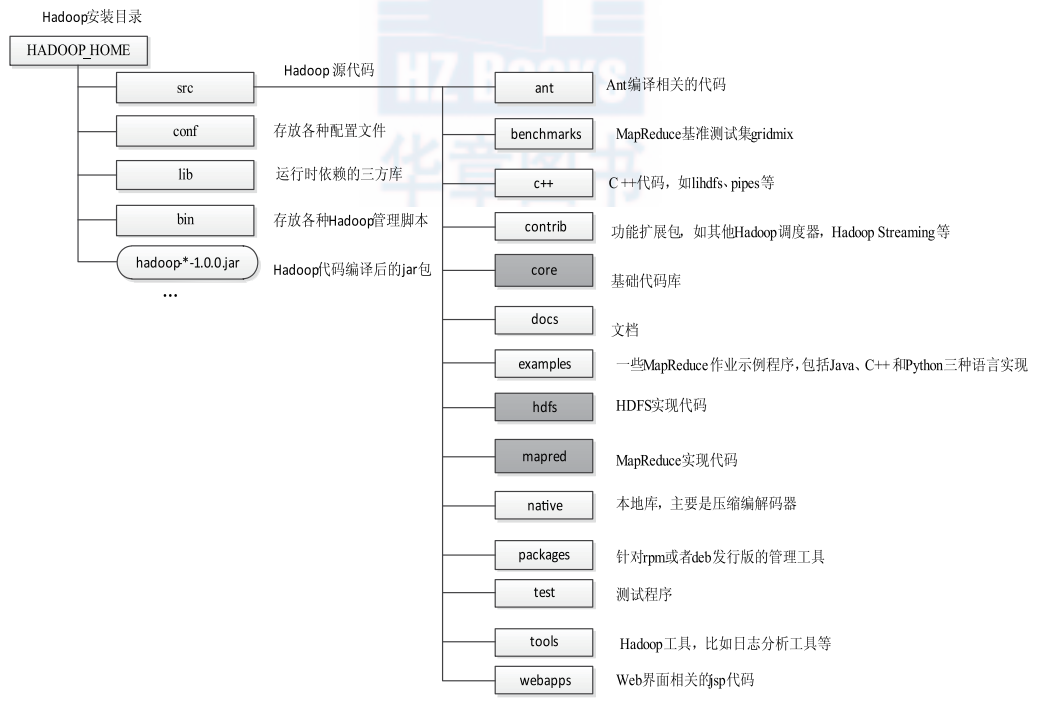
主要介绍src, conf, lib, bin:
- src :源代码目录。核心代码子目录是core、hdfs和mapred,分别实现了基础公共库、HDFS和MapReduce。
- conf:配置文件目录。如core-site.xml、hdfs-site.xml和mapred-site.xml的配置就在这里。
- lib:依赖的第三方库。包括jar包和其他动态库,通常在Hadoop启动或提交作业时自动加载。
- bin:脚本目录。
- hadoop:最基本最完备的管理脚本,大部分脚本都会调用它。
- start-all.sh/stop-all.sh 启动 / 停止所有节点上的 HDFS 和 MapReduce 相关服务。
- start-mapred.sh/stop-mapred.sh: 单独启动/停止MapReduce相关服务。
- start-dfs.sh/stop-dfs.sh: 单独启动/停止HDFS相关服务。
7. 简要描述HDFS的架构以及各组件功能。
Master/Slave架构,主要组件包括:Client、NameNode、Secondary NameNode和DataNode。
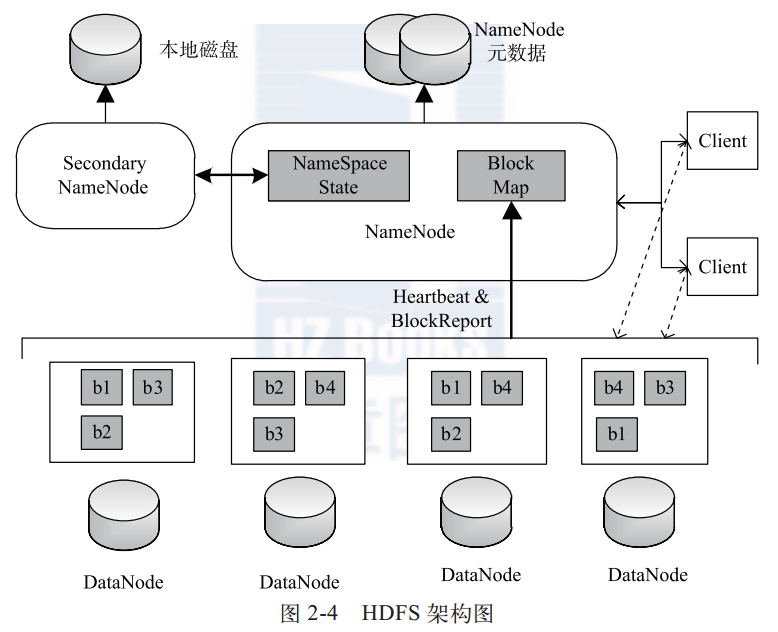
- Client:表示用户,于NameNode和DataNode进行交互访问HDFS中的文件。
- NameNode:名称节点。在集群中唯一存在,管理文件目录树和相关文件元数据信息。以上信息以“fsimage”(HDFS元数据镜像文件)和“editlog”(HDFS文件改动日志)形式存放在本地。HDFS重启会重新构造。
- Secondary NameNode:备份名称节点。但是最主要的任务是定期合并fsimage和edits日志,并传输给NameNode。
- DataNode:数据节点。负责实际数据存储,默认block大小是64MB,同一个block以流水线方式写到若干(默认3)个不同DataNode。
8. 简述MapReduce模型,并给出一个例子。
MapReduce由两个阶段组成 :Map和Reduce。
map()函数以key/value对作为输入,产生新系列的key/value对作为中间输出写入磁盘。
中间数据按照key值进行聚集,key相同的数据统一交给reduce()处理。reduce()过程还会进行排序,即shuffle()。
reduce()函数以key以及对应的value列表作为输入,合并相同键的值,形成新的键值对作为最终输出,存储到HDFS。
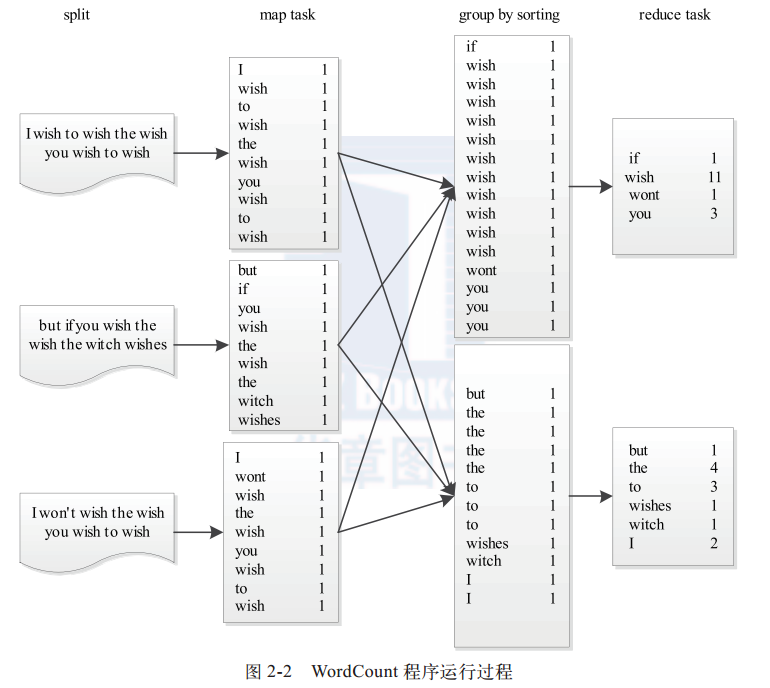
以WordCount为例,输入数据被切分成分片,每个分片交给一个Map Task处理,Map Task解析出键值对。根据Reduce Task个数将结果分成分片写入本地磁盘,Reduce Task读取自己的分片,然后进行reduce(),结果输出到文件中。
9. 如何写一个Hadoop MapReduce程序?结合源代码简要分析。
一个MapReduce程序需要5个组件:InputFormat(解析输入文件格式),Mapper(实现map()),Partitioner(处理分片),Reducer(实现reduce()),OutputFormat(解析输出文件格式)。
这些类新旧API中都有包含:
- org.apache.hadoop.mapred.lib.* :这一系列Java包提供了各种可直接在应用程序中使用的InputFormat、Mapper、Partitioner、Reducer和OuputFormat。
- org.apache.hadoop.mapreduce.* :这一系列Java包根据新版接口实现了各种InputFormat、Mapper、Partitioner、Reducer和OuputFormat。
Mapper类:
public class MyMapper<K extends WritableComparable, V extends Writable>
extends MapReduceBase implements Mapper<K, V, K, V> {
static enum MyCounters { NUM_RECORDS }
private String mapTaskId;
private String inputFile;
private int noRecords = 0;public void configure(JobConf job) {
mapTaskId = job.get(JobContext.TASK_ATTEMPT_ID);
inputFile = job.get(JobContext.MAP_INPUT_FILE);
}
public void map(K key, V val,
OutputCollector<K, V> output, Reporter reporter)
throws IOException {
// Process the <key, value> pair (assume this takes a while)
// ...
// ...
// Let the framework know that we are alive, and kicking!
// reporter.progress();
// Process some more
// ...
// ...
// Increment the no. of <key, value> pairs processed
++noRecords;
// Increment counters
reporter.incrCounter(NUM_RECORDS, 1);
// Every 100 records update application-level status
if ((noRecords%100) == 0) {
reporter.setStatus(mapTaskId + " processed " + noRecords +
" from input-file: " + inputFile);
}
// Output the result
output.collect(key, val);
}
}
Reduce类:
public class MyReducer<K extends WritableComparable, V extends Writable>
extends MapReduceBase implements Reducer<K, V, K, V> {
static enum MyCounters { NUM_RECORDS }
private String reduceTaskId;
private int noKeys = 0;
public void configure(JobConf job) {
reduceTaskId = job.get(JobContext.TASK_ATTEMPT_ID);
}
public void reduce(K key, Iterator<V> values, OutputCollector<K, V> output, Reporter reporter)
throws IOException {
// Process
int noValues = 0;
while (values.hasNext()) {
V value = values.next();
// Increment the no. of values for this key
++noValues;
// Process the <key, value> pair (assume this takes a while)
// ...
// ...
// Let the framework know that we are alive, and kicking!
if ((noValues%10) == 0) {
reporter.progress();
}
// Process some more
// ...
// ...
// Output the <key, value>
output.collect(key, value);
}
// Increment the no. of <key, list of values> pairs processed
++noKeys;
// Increment counters
reporter.incrCounter(NUM_RECORDS, 1);
// Every 100 keys update application-level status
if ((noKeys%100) == 0) {
reporter.setStatus(reduceTaskId + " processed " + noKeys);
}
}
}
Reducer有三个步骤:
- Shuffle。Reducer的输入是Mapper的分组输出(所以类型要相同)。对于每个Reducer,这一步要取出所有Mapper(s)的输出中相联系的部分(可能就是指键相同的)。
- Sort。按照键排序。排序的实现方法可能是一个Comparator :JobConf.setOutputValueGroupingComparator(Class)。(JobConf指定作业各种参数)
- Reduce。每个对<key, (list of values)> 都调用reduce(Object, Iterator, OutputCollector, Reporter),然后输出写入FileSystem,即OutputCollector.collect(Object, Object)。(输出没有重排序)
10. 简要描述Hadoop MapReduce的架构和主要组件。
Master/Slave架构,主要组件有Client、JobTracker、TaskTracker和Task。
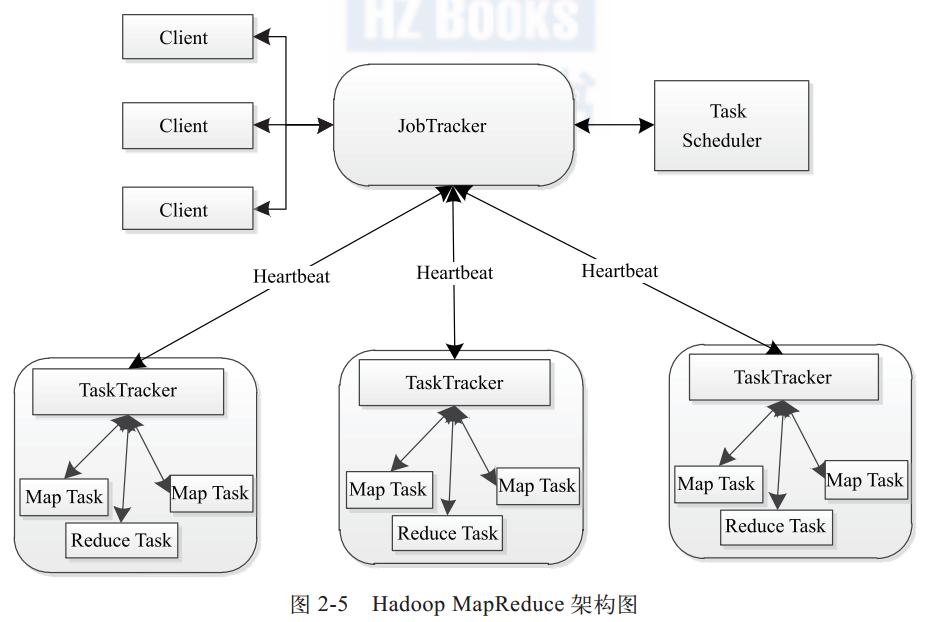
- Client:MapReduce程序通过Client提交到JobTracker,即提交一个作业Job。Job会被分解为若干个任务Task。
- JobTracker:资源监控和作业调度。JobTracker监控所有TaskTracker与作业的健康状况, 一旦发现失败情况后, 其会将相应的任务转移到其他节点;同时, JobTracker会跟踪任务的执行进度、 资源使用量等信息, 并将这些信息告诉任务调度器, 而调度器会在资源出现空闲时, 选择合适的任务使用这些资源。
- TaskTracker:TaskTracker周期性通过Heartbeats将本节点的资源使用情况以及任务运行进度回报给JobTracker,同时接受JobTracker发送的命令执行相应操作。资源量(CPU、内存)用slot划分,一个Task获取一个slot采用机会运行。slot也分为Map slot和Reduce slot。Task的并发度可以通过配置slot数目限定。
- Task:分为Map Task和Reduce Task,由TaskTracker启动。
11. 作业Job和任务Task的区别和联系是什么?
作业Job实质是用户提交给JobTracker的MapReduce程序,JobTracker会将一个Job分解成若干个Map Task和Reduce Task交给TaskTracker执行调度。
Map Task执行过程:
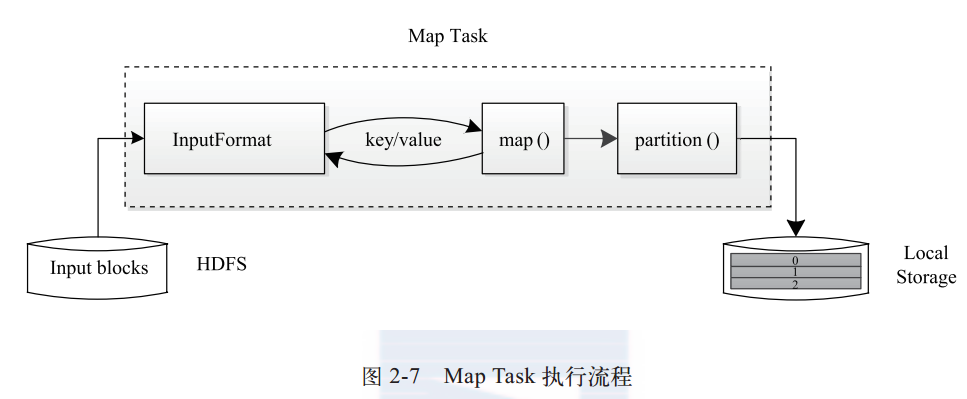
Map Task先将对应split迭代解析成一系列键值对,调用用户定义的map()函数进行处理,最终将临时结果存储到本地。这些数据被分成若干partition,每个partition对应一个Reduce Task。
Reduce Task执行过程:
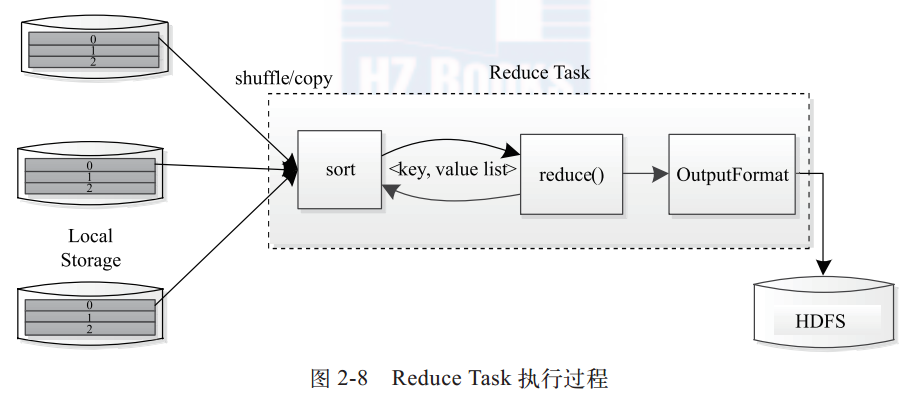
Reduce Task分为三个阶段:Shuffle阶段读取远程节点上的Map Task的输出;Sort阶段根据key对键值对排序;Reduce阶段依次读取<key, value list>,调用用户定义的reduce()函数处理,并将最终输出存储到HDFS。
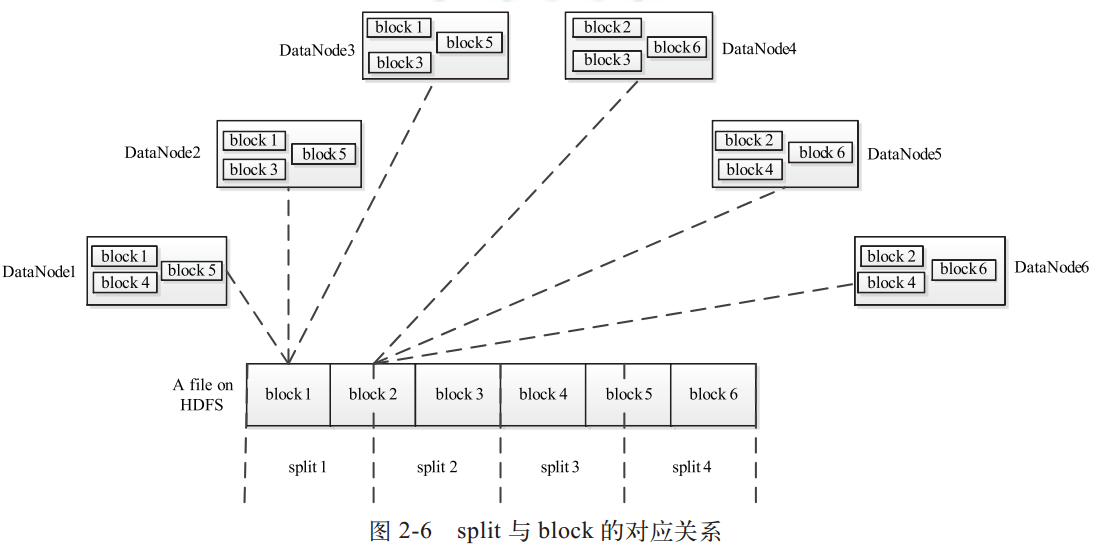
12. 什么是split?什么是block?
HDFS以固定大小的block(64MB)为基本单位存储数据。
MapReduce的处理单位则是split。split是一个逻辑概念,它只包含一些元数据信息,比如数据起始位置、数据长度、数据所在节点等。划分方法完全由用户自己决定。split的多少决定了Map Task的数目,因为每个split会交由一个Map Task处理。
它们的关系如下:
13. Hadoop MapReduce是怎么实现分布化的?
- 通过作业和任务
Job是客户端执行的单位,作业分为若干Task工作(Map和Reduce)。
两种类型的节点控制作业执行过程:Jobtracker和多个Tasktracker。
map任务受数据局部性影响,本地数据读取更快,reduce任务则无所谓,因为要处理全局数据。因此,map任务直接输出到磁盘,任务完成后删除,reduce任务输出到HDFS。
单一reduce任务数据流:
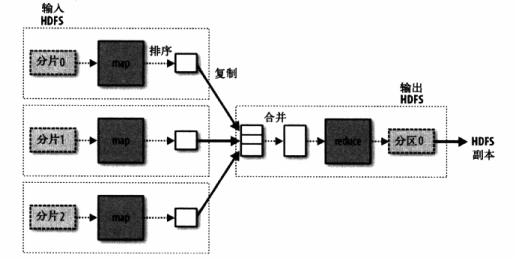
多reduce任务数据流:
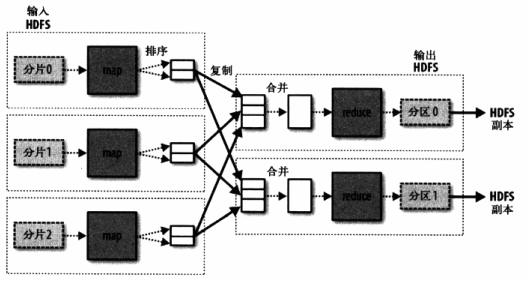
- 通过分片(split)
Hadoop中,输入数据划分为登场小数据发送至MapReduce,称为分片。每个分片都会创建一个map任务。
分片越小,并行处理效率越高,但管理分片的时间和map任务创建时间越多。理想分片大小通常是HDFS块(block)大小,默认64MB。
14. 简述MapReduce框架中的心跳机制。
MapReduce 通过心跳机制给TaskTracker分配任务,使JobTracker能及时获取各个节点的资源使用情况和任务运行状态信息、判断TaskTracker死活。
JobTracker不会主动向TaskTracker发送心跳信息,而是TaskTracker周期性调用心跳RPC函数,汇报节点和任务运行状态信息,同时领取JobTracker返回心跳包的各种命令。
- TaskTracker端
TaskTracker中有一个run()方法,其维护了一个无限循环用于通过心跳发送任务运行状态信息和接收JobTracker通过心跳返回的命令信息:
/**
* The server retry loop.
* This while-loop attempts to connect to the JobTracker. It only
* loops when the old TaskTracker has gone bad (its state is
* stale somehow) and we need to reinitialize everything.
*/
public void run() {
try {
getUserLogManager().start();
startCleanupThreads();
boolean denied = false;
while (running && !shuttingDown && !denied) {
boolean staleState = false;
try {
// This while-loop attempts reconnects if we get network errors
while (running && !staleState && !shuttingDown && !denied) {
try {
State osState = offerService();
if (osState == State.STALE) {
staleState = true;
} else if (osState == State.DENIED) {
denied = true;
}
....}
并提供一个服务函数offerService()用于处理心跳相关信息:
/**
* Main service loop. Will stay in this loop forever.
*/
State offerService() throws Exception {
long lastHeartbeat = System.currentTimeMillis();//上一次发心跳距现在时间
////此循环主要根据控制完成task个数控制心跳间隔。
while (running && !shuttingDown) {
try {
long now = System.currentTimeMillis();//获得当前时间
// accelerate to account for multiple finished tasks up-front
//通过完成的任务数动态控制心跳间隔时间
long remaining =
(lastHeartbeat + getHeartbeatInterval(finishedCount.get())) - now;
while (remaining > 0) {
// sleeps for the wait time or
// until there are *enough* empty slots to schedule tasks
synchronized (finishedCount) {
finishedCount.wait(remaining);
// Recompute
now = System.currentTimeMillis();
remaining =
(lastHeartbeat + getHeartbeatInterval(finishedCount.get())) - now;
if (remaining <= 0) {
// Reset count
finishedCount.set(0);
break;
}
}
}
...
//发送心跳
// Send the heartbeat and process the jobtracker's directives
HeartbeatResponse heartbeatResponse = transmitHeartBeat(now);//真正想JobTracker发送心跳
.....
//开始处理JobTracker返回的命令
TaskTrackerAction[] actions = heartbeatResponse.getActions();
...
//杀死一定时间没没有汇报进度的task
markUnresponsiveTasks();
//当剩余磁盘空间小于mapred.local.dir.minspacekill(默认为0)时,寻找合适的任务将其杀掉以释放空间
killOverflowingTasks();
TaskTracker向JobTracker发送一次心跳的流程如下:

需要注意的有以下几个重要过程:
1.判断是否达到心跳间隔。
TaskTracker的心跳间隔与task完成情况以及整个集群规模规模有关,源码提供一种“outOfBand”机制动态缩短TaskTracker发送心跳的间隔。
从offerService()里可以找到一个getHeartbeatInterval(finishedCount.get())方法,这个方法会动态调整心跳,其中finishedCount.get()是已完成Task的计数。
2.判断TaskTracker是否第一次启动。
如果是第一次启动的话则会检测当前的TaskTracker版本是否和JobTracker的版本是否一致,如果版本号一致才会向JobTracker发送心跳。
3.检测磁盘是否读写正常。
MapReduce框架中,在map任务计算过程中会将输出结果保存在mapred.local.dir指定的本地目录中,TaskTracker初始化时会对这些目录进行一次检测,之后,TaskTracker会周期性(由mapred.disk.healthChecker.interval配置,默认60s)地对这些正常目录进行检测,如果发现故障目录,TaskTracker就会重新对自己进行初始化。
4.发送心跳。
TaskTracker将当前节点运行时信息,例如TaskTracker基本情况、资源使用情况、任务运行状态等,通过心跳信息向JobTracker进行汇报,同时接受来自JobTracker的各种指令。
TaskTracker基本情况、资源使用情况、任务运行状态等信息会被封装到一个可序列化的类TaskTrackerStatus中,并会伴随心跳发送给JobTracker。每次发送心跳时,TaskTracker根据最新的信息重新构造TaskTrackerStatus。
但不是每次心跳都会发送节点资源信息申请新的Task,只有当存在空闲的map或者reduce slot,并且map输出目录大于mapred.local.dir.minspackekill才会将上面的节点资源信息放到TaskTrackerStatus中,向JobTracker发送节点资源使用情况申请新任务。
- JobTracker端
JobTracker端的主要任务是处理TaskTracker发送的心跳信息,判断TaskTracker是否存活,及时让JobTracker获取到各个节点上的资源使用情况和任务运行情况和为TaskTracker下达各种命令等功能。
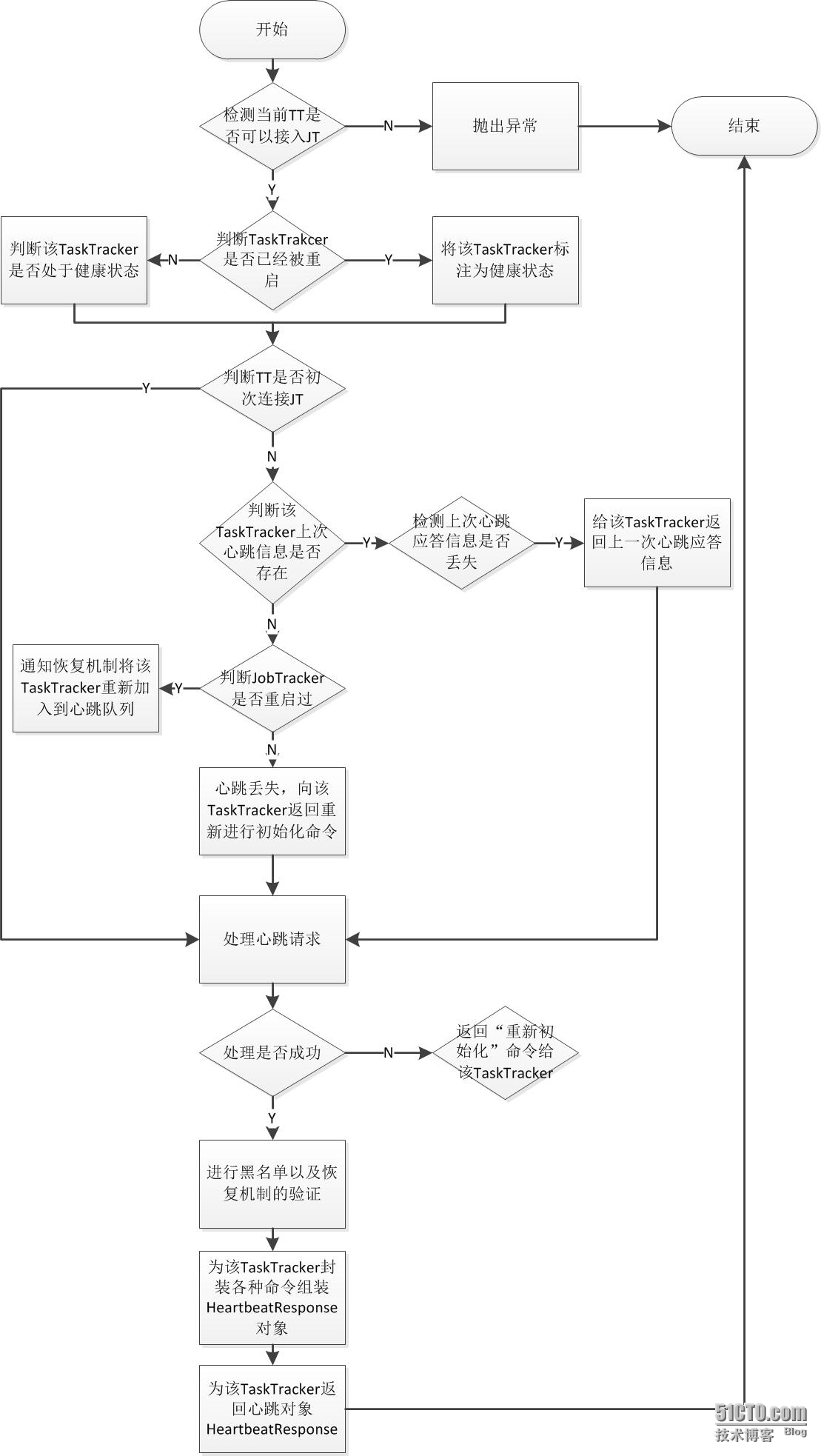
JobTracker处理心跳的主要函数是heartbeat方法,流程如下:
需要注意的主要过程:
- 检测当前TaskTracker是否可以接入JobTracker。
当且仅当该TaskTracker在host list(由参数mapred.hosts配置)中,但是不在exclude list(由mapred.hosts.exclude指定)中,才允许接入。如果不允许接入则会直接抛出异常终止本次心跳处理。
- 检测TaskTracker是否已经被重启
在JobTracker允许TaskTracker接入的前提下,检查是否重启过的restarted参数有TaskTracker通过心跳传给JobTracker。如果TaskTracker被重启过,则将之标注为健康状态的TaskTracker,并且从黑名或者灰名单中清除,否则启动容错机制以检测它是否处于健康状态。
- 检测TaskTracker是否是第一次连接JobTracker。
这是一个容错步骤。心跳机制中,如果JobTracker收到的不是初次心跳,那trackerToHeartbeatResponseMap对象会保存该TaskTracker上一次心跳应答对象信息HeartbeatResponse,而初次心跳就不会有上一次的应答对象信息。但是JobTracker端记录的该TaskTracker状态不一定是一致的,所以需要容错处理。
if (initialContact != true) {//该TaskTracker不是是第一次连接JobTracker
// If this isn't the 'initial contact' from the tasktracker,
// there is something seriously wrong if the JobTracker has
// no record of the 'previous heartbeat'; if so, ask the
// tasktracker to re-initialize itself.
//TaskTracker非第一次连接JobTracker,并且上一次心跳应答对象为空
if (prevHeartbeatResponse == null) {
// This is the first heartbeat from the old tracker to the newly
// started JobTracker
if (hasRestarted()) {//判断JobTracker是否重启过
addRestartInfo = true;
// inform the recovery manager about this tracker joining back
recoveryManager.unMarkTracker(trackerName);
} else {//心跳丢失,向该TaskTracker返回重新进行初始化命令
// Jobtracker might have restarted but no recovery is needed
// otherwise this code should not be reached
LOG.warn("Serious problem, cannot find record of 'previous' " +
"heartbeat for '" + trackerName +
"'; reinitializing the tasktracker");
return new HeartbeatResponse(responseId,
new TaskTrackerAction[] {new ReinitTrackerAction()});
}
} else {//TaskTracker非第一次连接JobTracker,并且上一次心跳应答对象不为空
// It is completely safe to not process a 'duplicate' heartbeat from a
// {@link TaskTracker} since it resends the heartbeat when rpcs are
// lost see {@link TaskTracker.transmitHeartbeat()};
// acknowledge it by re-sending the previous response to let the
// {@link TaskTracker} go forward.
//判断JobTracker端的上一次对该TaskTracker的心跳应答ID是否与该TaskTracker带过来的应答ID一致
if (prevHeartbeatResponse.getResponseId() != responseId) {//不一致,属于丢失心跳情况,返回上一次心跳信息给该TaskTracker
LOG.info("Ignoring 'duplicate' heartbeat from '" +
trackerName + "'; resending the previous 'lost' response");
return prevHeartbeatResponse;
}
}
}
...
- 处理心跳请求
根据心跳带来的TraskTracker状态信息去更新当前集群的资源使用情况、Task信息和节点健康信息:
// Process this heartbeat
short newResponseId = (short)(responseId + 1);//心跳相应加1
//记录心跳的发送时间,以便发现在一定时间内未发送心跳的TaskTracker,并将之标注为死亡状态,以后不再向其分配新的Tasks
status.setLastSeen(now);
if (!processHeartbeat(status, initialContact, now)) {
//如果存在针对该TaskTracker的上一次心跳应答时,将其清空以便将新的应答放进来
if (prevHeartbeatResponse != null) {
trackerToHeartbeatResponseMap.remove(trackerName);
}
//当处理心跳请求失败时将返回“重新初始化”给该TaskTracker
return new HeartbeatResponse(newResponseId,
new TaskTrackerAction[] {new ReinitTrackerAction()});
}
- 下达命令给TaskTracker
该过程主要是遍历JobTracker中的各种对象映射集合,取得相关命令,然后为TaskTracker下达命令。
命令种类有以下几种: * ReinitTrackerAction,重新初始化命令。 * LaunchTaskAction,该类封装了TaskTracker分配的新任务,新任务的类型分两种:计算型任务和辅助型任务。 * KillTaskAction,该类封装了TaskTracker需要杀死的任务。其中计算型任务负责处理实际数据的任务,也就是的Reduce和Map任务,由专门的任务调度器去调用(默认是FIFO调度器)。另外辅助型任务包括:job-setup task、job-cleanup task和task-cleanup task三种。task-cleanup task的主要作用是清理失败的map或者reduce任务的部分结果数据,它由jobTracker直接调度,而且其调度的优先级比map和reduce任务都要高。至于job-setup task和job-cleanup task任务的作用我认为比较简单,主要是标志map和reduce作业运行开始和运行结束的同步标志。jobTracker为一个有空闲slot并且不在黑名单中的taskTracker分配任务的选择顺序是先辅助型任务然后计算型任务.
15. 如何提交一个MapReduce作业(Job)?
JobClient的runJob()方法(JobClient.runJob(conf))可以新建一个JobClient实例并调用JobTracker.submitJob()方法。runJob()每秒轮询作业的进度,如果发现上报信息相比上一次有改动,会把进度报告输出到控制台。作业完成后,如果成功显示作业计数器,失败输出错误。
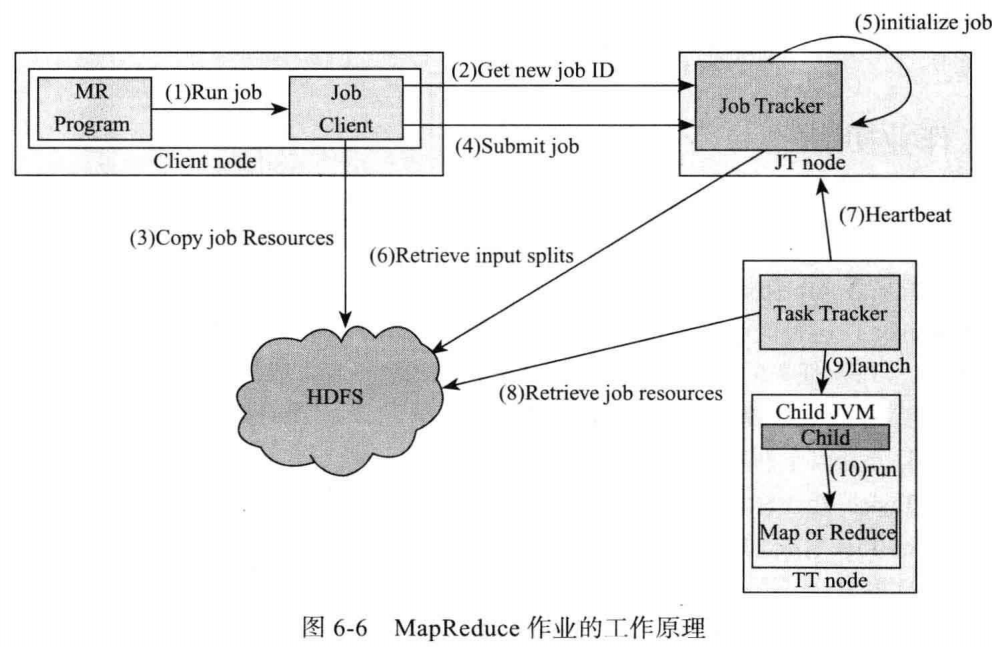
JobClient提交作业的过程如下: 1. 向JobTracker请求一个新作业ID(JobTracker.getNewJobId())。 2. 检查作业输出说明。 3. 计算作业输出划分。 4. 将运行作业需要的资源备份,复制到一个以作业ID命名的目录中。 5. 调用JobTracker.submitJob()方法,通知JobTracker作业准备执行。 6. JobTracker把submitJob()调用放入内部队列,交由作业调度器调度。 7. 作业调度器从共享文件系统(HDFS)获取JobClient计算好的输入划分信息,创建运行任务列表,为每个划分创建一个Map任务。创建的Reduce任务数量由JobConf的mapred.reduce.tasks属性决定。 8. TaskTracker定期发送心跳给JobTracker,汇报当前状态,如果正常,JobTracker为TaskTracker分配一个任务。
一般来说,提交作业时可以写一个驱动Driver类继承Configured类实现Tool接口:(例子来自Apache Hadoop 2.7.2 官方文档)
public class MyApp extends Configured implements Tool {
public int run(String[] args) throws Exception {
// Configuration processed by ToolRunner
Configuration conf = getConf();
// Create a JobConf using the processed conf
JobConf job = new JobConf(conf, MyApp.class);
// Process custom command-line options
Path in = new Path(args[1]);
Path out = new Path(args[2]);
// Specify various job-specific parameters
job.setJobName("my-app");
job.setInputPath(in);
job.setOutputPath(out);
job.setMapperClass(MyMapper.class);//设置Mapper类
job.setReducerClass(MyReducer.class);//设置Reducer类
// Submit the job, then poll for progress until the job is complete
JobClient.runJob(job);//调用JobClient.runJob()
return 0;
}
public static void main(String[] args) throws Exception {
// Let ToolRunner handle generic command-line options
int res = ToolRunner.run(new Configuration(), new MyApp(), args);
System.exit(res);
}
}
把程序打包之后,就可以使用hadoop jar命令启动作业了。
16. TaskTracker运行任务的步骤是怎样的?
TaskTracker运行任务的步骤:
- 本地化作业的JAR文件,将其从共享文件系统复制到TaskTracker所在的文件系统。同时将应用程序需要的全部文件从分布式缓存复制到本地。
- 新建一个本地工作目录,将JAR文件中的内容加压到该目录。
- 新建一个TaskRunner实例运行任务。TaskRunner会启动一个新JVM来运行任务。不同任务重用JVM是可能的。
17. Hadoop MapReduce作业的运行过程是怎样的?简述MapReduce作业的生命周期。
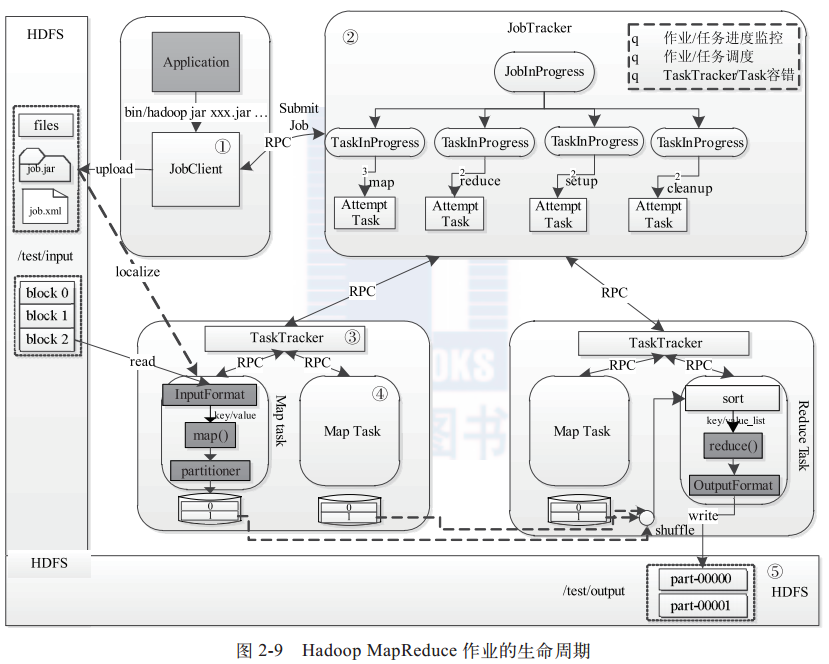
作业生命周期分为5个过程:
- 作业提交和初始化。(详细介绍见问题15)JobClient实例将作业相关资源上传到HDFS,通过RPC通知JobTracker。JobTracker收到提交请求,由作业调度模块对作业初始化,为作业创建一个JobInProgress对象跟踪运行情况,JobInProgress为每个Task创建TaskInProgress跟踪任务运行状态。
- 任务调度与监控。任务调度和监控功能由JobTracker完成,TaskTracker通过心跳周期性汇报本节点情况,出现空闲slot,JobTracker根据一定策略选择合适任务执行。
- 任务环境准备。JVM启动和资源隔离,由TaskTracker实现。每个Task都会启动一个JVM。
- 任务执行。Task进度由Task通过RPC汇报给TaskTracker,再通过心跳上报JobTracker。
- 作业完成。所有Task执行完毕,作业才会成功。