我是怎么在Docker上搭建Hadoop的——Hadoop伪分布式安装
2016-06-06
写在前面:Docker上搭Hadoop实际上是个很蛋疼的做法,其实本次实验只是为了学习Docker……
0. 版本说明
- CentOS 7.0 - 阿里云主机
- Docker 1.9.1
1. 安装Docker
CentOS 7.0安装Docker很简单:
sudo yum install docker
docker -v
docker info

docker daemon
ps aux | grep docker

docker info
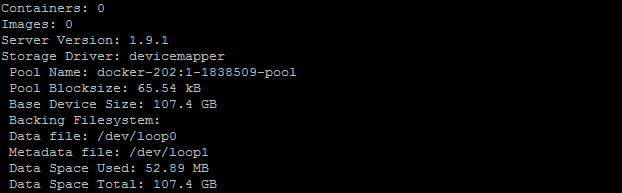
CentOS 6.5要麻烦一些:
rpm -Uvh http://download.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm
yum install docker-io
2. 获取镜像
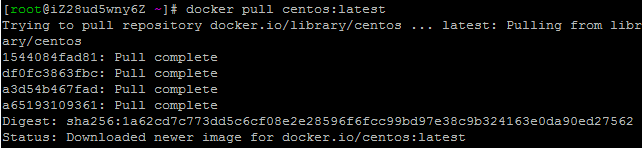
docker pull centos:latest

3. 启动容器
docker run -it centos /bin/bash
就可以基于镜像启动容器了。这个命令等价于
docker create -it centos:last
docker start centos
4. 下载Hadoop镜像
这里我们就不再自己部署Hadoop了,直接使用https://github.com/kiwenlau提供的镜像。没错我就是懒。
docker pull index.alauda.cn/kiwenlau/hadoop-master:0.1.0
docker pull index.alauda.cn/kiwenlau/hadoop-slave:0.1.0
docker pull index.alauda.cn/kiwenlau/hadoop-base:0.1.0
docker pull index.alauda.cn/kiwenlau/serf-dnsmasq:0.1.0
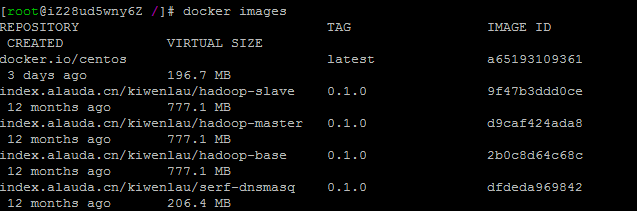
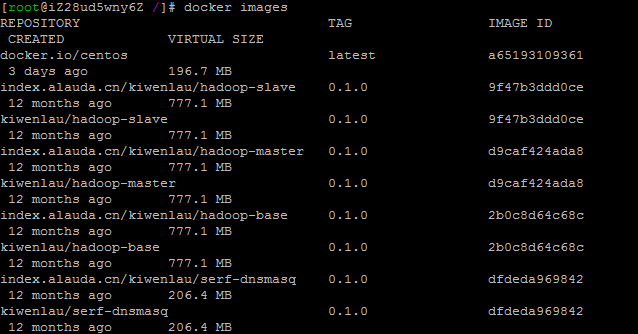
根据镜像ID修改镜像tag:
docker tag 9f47b3ddd0ce kiwenlau/hadoop-slave:0.1.0
docker tag d9caf424ada8 kiwenlau/hadoop-master:0.1.0
docker tag 2b0c8d64c68c kiwenlau/hadoop-base:0.1.0
docker tag dfdeda969842 kiwenlau/serf-dnsmasq:0.1.0
5. 三节点集群搭建和管理
kiwenlau/hadoop-cluster-docker这个开源项目提供了Hadoop集群搭建和管理的脚本。我们可以直接下载:
git clone https://github.com/kiwenlau/hadoop-cluster-docker
cd hadoop-cluster-docker
./start-container.sh
这个脚本是是用来启动容器的,源码如下:
#!/bin/bash
# run N slave containers
N=$1
# the defaut node number is 3
if [ $# = 0 ]
then
N=3
fi
# delete old master container and start new master container
sudo docker rm -f master &> /dev/null
echo "start master container..."
sudo docker run -d -t --dns 127.0.0.1 -P --name master -h master.kiwenlau.com -w /root kiwenlau/hadoop-master:0.1.0 &> /dev/null
# get the IP address of master container
FIRST_IP=$(sudo docker inspect --format="" master)
# delete old slave containers and start new slave containers
i=1
while [ $i -lt $N ]
do
sudo docker rm -f slave$i &> /dev/null
echo "start slave$i container..."
sudo docker run -d -t --dns 127.0.0.1 -P --name slave$i -h slave$i.kiwenlau.com -e JOIN_IP=$FIRST_IP kiwenlau/hadoop-slave:0.1.0 &> /dev/null
i=$(( $i + 1 ))
done
# create a new Bash session in the master container
sudo docker exec -it master bash
可以看到脚本默认启动一个Master节点和两个Slaver节点,并且启动时会删除旧Master节点和旧Slaver节点。
运行结束后,会进入Master节点的Bash。执行
root@master:~# serf members
可以查看节点信息。
6. 测试Hadoop
然后就可以测试Hadoop了,使用的用例依然是WordCount……
root@master:~# ./start-hadoop.sh
root@master:~# ./run-wordcount.sh
ctrl+d可以退出容器,ctrl+Q+P可以退出不停止。
7. 删除容器
查看处于终止状态的容器:
docker ps -a
删除容器:
docker rm 2142b46fd80f
docker rm 96e2417ba9c1
docker rm c0f08be08825
8. 存在问题
我希望的结果是在一台机器运行Docker+Hadoop Master,其余几台机器运行Docker+Hadoop Slaver,免去重复部署的工作,所以未来要解决的是不同主机上容器的通信问题。
Docker容器是从宿主主机的网桥接口桥接虚拟接口,从地支持配置一个IP地址,理论上是可行的。(另外,本次实验各个节点分配到的都是局域网IP。我猜测不同主机的容器应该可以通过映射的端口通信。也可以看一下http://www.infoq.com/cn/articles/docker-network-and-pipework-open-source-explanation-practice)