Hadoop集群部署
2016-06-08
写在前面:如果有不明白的地方,请查看Hadoop 2.7.2官方文档。
0. 版本说明
- CentOS 7.0 - 阿里云主机
- CentOS 6.5 - 腾讯云主机
- Hadoop 2.7.2
- JRE 1.7.0_75
其中,阿里云主机是Master节点,既作为名称节点,又作为数据节点。腾讯云主机是Slaver节点,作为数据节点。
1. 安装JDK和JRE
我使用的镜像竟然没有安装Java,所以需要安装JDK和JRE。
rpm -ivh jre-7u75-linux-x64.rpm
rpm -ivh jdk-7u75-linux-x64.rpm
java -version

vi /etc/profile配置JAVA_HOME环境变量:
export JAVA_HOME=/usr/java/jdk1.7.0_75
保存然后sourve /etc/profile。
2. 下载Hadoop
从Apache Hadoop发行页下载最新Hadoop,我们这里使用的是Hadoop 2.7.2。
将Hadoop在/usr/local目录下解压:
cd /usr/local
wget http://apache.fayea.com/hadoop/common/hadoop-2.7.2/hadoop-2.7.2.tar.gz
tar -zxvf hadoop-2.7.2.tar.gz
3. 配置环境变量
export HADOOP_HOME=/usr/local/hadoop-2.7.2
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
export HADOOP_LOG_DIR=/var/log/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
然后保存并source /etc/profile。
4. 建立SSH
在Master节点上创建SSH密钥对(无密码)并发送给其他节点。
ssh keygen
ssh-copy-id localhost
ssh-copy-id slaver
5. 配置xml文件
以下操作均在Master节点执行。
5.1 创建存储目录
mkdir /usr/hadoop/datanode
mkdir /usr/hadoop/namenode
ssh slaver "mkdir /usr/hadoop/datanode"
5.2 hdfs-site.xml文件
hdfs-site.xml是HDFS后台程序设置,可以配置名称节点、第二名称节点和数据节点。官方文档给的配置说明:
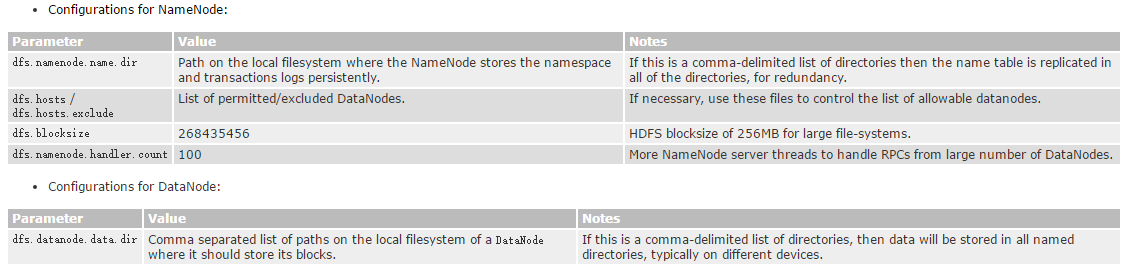
vi /usr/local/hadoop-2.7.2/etc/hadoop/hdfs-site.xml加入以下配置:
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///usr/hadoop/datanode</value>
</property>
</configuration>
dfs.replication参数是HDFS的数据块复制份数,默认是3。将配置发给Slaver节点:
scp usr/local/hadoop-2.7.2/etc/hadoop/hdfs-site.xml slaver:usr/local/hadoop-2.7.2/etc/hadoop/
然后再在Master节点的配置中加入namenode的配置:
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///usr/hadoop/namenode</value>
</property>
</configuration>
5.3 core-site.xml文件
core-site.xml是Hadoop核心的配置,例如HDFS和MapReduce中I/O配置。

vi /usr/local/hadoop-2.7.2/etc/hadoop/core-site.xml加入以下配置:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000/</value>
</property>
</configuration>
然后发送给Slaver节点:
scp usr/local/hadoop-2.7.2/etc/hadoop/core-site.xml slaver:usr/local/hadoop-2.7.2/etc/hadoop/
5.4 mapred-site.xml文件
mapred-site.xml文件是MapReduce后台程序设置的配置,包括jobtracker和tasktracker。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
以上配置的意思是MapReduce的执行框架设置为Hadoop YARN。
5.5 yarn-site.xml文件
yarn-site.xml文件是ResourceManager and NodeManager的设置。
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master:8088</value>
</property>
<property>
<name>yarn.nodemanager.hostname</name>
<value>master:50070</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
yarn.nodemanager.aux-services表示MapReduce应用需要设置Shuffle服务。
5.6 slaves文件
最后在slaves文件中加入所有节点的主机名orIP,并删除localhost。
6. 运行Hadoop
依次格式化名称节点,启动dfs,启动YARN,查看状态:
hdfs namenode -format
start-dfs.sh
start-yarn.sh
jps
结果显示:

7. 测试Hadoop
新建文件夹:
hdfs dfs -mkdir /test
如果出现这样的结果:

强制离开安全模式:
hadoop dfsadmin -safemode leave
如果还是出现上述提示可以尝试杀死进程。
查看文件列表:

可以尝试执行一个测试程序(当然是WordCount)
hdfs dfs -copyFromLocal $HADOOP_HOME/NOTICE.txt /test
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /test/NOTICE.txt /output01
然后查看执行结果:
hdfs dfs -ls /output01
hdfs dfs -cat /output01/part-r-00000
