数据挖掘笔记 - 关联规则挖掘
2016-06-15
1. 相关概念
1.1 频繁模式
频繁模式(frequent pattern)是频繁出现在数据集中的模式(比如项集、子序列或子结构)。
1.2 关联规则
关联规则(association rule)用来表示数据项之间的相关性。
其实就是事件A和B的先验/后验概率。
支持度(support)和置信度(confidence)是规则兴趣度的两种度量,分别反映规则的有用性和确定性。
支持度:所有事务中,AB事件发生的百分比($P(AB)$)。
置信度:$P(AB)/P(A)$。
如果关联规则满足最小支持度阈值和最小置信度阈值,则认为关联规则是有趣的,即强规则。
1.3 频繁项集和强关联规则
项的集合称为项集,$k$个项的项集称为$k$项集。项集的相对支持度满足最小支持度阈值就是频繁项集。
关联规则挖掘一般有两步: 1. 找出所有频繁项集;(开销较大) 2. 由频繁项集产生强关联规则。
极大频繁项集:本身是频繁的,并且不存在包含它的超集是频繁的。
2. Apriori算法
2.1 Apriori算法步骤
Apriori使用逐层搜索的方法,用k项集探索k+1项集。
基于先验性质(频繁项集的所有非空子集也一定是频繁的),Apriori分为两步:连接步和剪枝步。
下面举个例子,其实很简单:
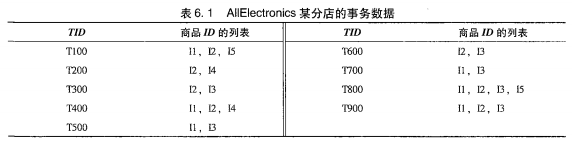
上图是事务列表,下面是迭代过程:
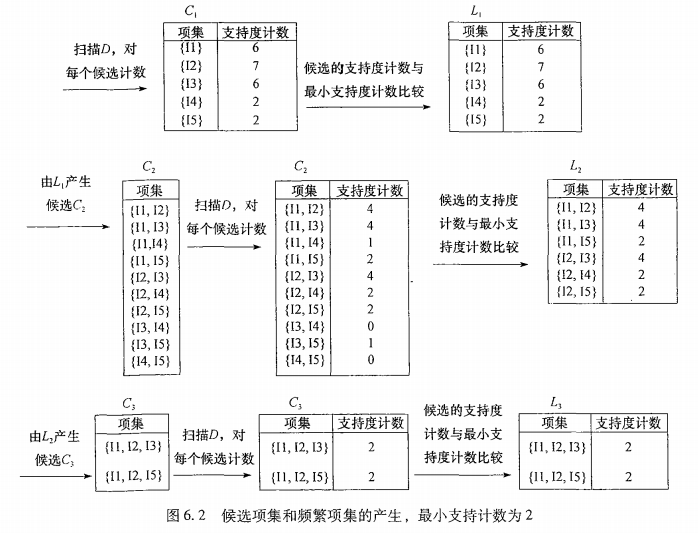
从$k=1$开始,$min_sup$设为2,遍历事务表,统计频数得到$C{1}$,剪枝得到$L{1}$。$L{1}\bowtie L{1}$连接得到$C{2}$键值,然后计数。剪枝就得到 $L{2}$。一直到$C_{k}=\phi $终止,找出了所有的频繁项集。
2.2 由频繁项集产生关联规则
计算置信度:
$$confidence({A}\Rightarrow{B})=P(A|B)=\frac{support_count(A\cup{B})}{support_count(A)}$$
满足最小置信度阈值就是强规则了。
2.3 提高Apriori算法效率
基于散列:第一次遍历时,由$C_{1}$产生频繁1项集时,将所有2项集Hash计数,低于支持度阈值的从侯选集删除。如
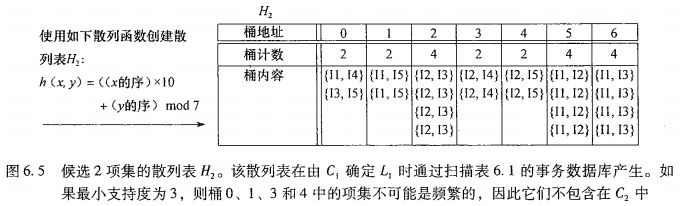
事物压缩:不包含k项集的事务不可能包含任何k+1项集,下一步迭代就可以删除。
其他还有抽样、分区、动态计数方法,不一一讲述。
3. FP-growth算法
FP(Frequent-Pattern)-growth算法可以看成两步:构造FP树和挖掘FP树。
3.1 FP树构造
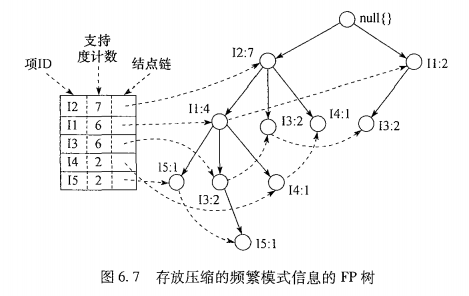
其实过程很简单: 1. 遍历事务,找出频繁1项集并计数排序。 2. 新建一个null的根节点。 3. 再次遍历所有事务,创建分支。每个事务的项都按图6.7左边的排序处理(即降序),比如T1:12,11,15,null->12->11->15,T2:12,14,null->12->14。每个事务的分支加入树中时,按照最大共享前缀进行链接(就像KMP字符串匹配)。并且,树中的每个节点有事务的分支路径加入时,计数加1。比如:
Start, FP:null;
T1, FP:null->12->11->15;
T2, FP:null->12->11->15
~ ->14;
T3, FP:null->12->11->15
~ ->13
~ ->14;
T4, FP:null->12->11->15
~ ->13
~ ->14;
T5, FP:null->12->11->15
| ~ ->13
| ~ ->14;
~ ----->11->13
···
- 最后,为了方便遍历创建项头表。每项通过结点链指向它在树中的位置。
3.2 FP树挖掘
仍然以3.1小节为例,按照升序顺序,依次挖掘图6.7中的节点。
比如第一个是15,构造他的条件FP树。将15作为后缀,找出所有前缀路径:<12, 11, 15:1>和<12, 11, 13, 15:1>。然后用上一小节的办法构造FP树。注意,最后将不满足最小支持度的路径舍弃。所以实际剩下的FP树是
FP:null->12->11->15
该树产生的频繁模式的所有组合:{11, 15:2},{12, 15:2},{12, 11, 15:2}。后缀必须是条件FP树对应的节点。
把所有节点的频繁模式都找到,即是最后的结果。